We haven’t written any technical blogs about how we play with data. In this quick post I explain how I managed to create a database of addresses of all the early childhood development centres in Zululand.
Some background
We are currently working on a project to find previously invisible early childhood development centres (ECD) in rural KwaZulu Natal. An ECD centre is basically a nursery school, day care centre, creche, etc. I will write about the project in more detail in a future blog but the short summary is that we are experimenting with crowdsourcing. We are going to ask communities to identify their local ECD centres so that we can pin them to a map. There are a bunch of good reasons why such a map might be important although I won’t go into the details here.
The project is experimental and we are trying to answer a number of questions so that we can evaluate whether this method of identifying centres can be scaled up nationally. One of the questions revolves around data quality and completeness. How good is the data that we are able to crowd source?
One way of answering this question is to create a known-centres database containing a list of all the ECD centres that we already know about. We then compare our crowdsourced data with data from this database. If our crowdsourcing is successful, our collected data should include a large number of centres from the known-centres database.
If it doesn’t, then our crowdsourced data is not complete. If the two datasets do match up, then we should have a degree of confidence that our project is succeeding. There are some problems with that assumption due to selection bias, etc but we’ll ignore that for now.
So how do we go about creating our known-centres database?
Grab an NPO Database
Many ECD centres are registered as NPOs. The Department of Social Development maintains a database of NPOs here. Thankfully, Friedrich Lindenberg scraped this database last year which makes it easy for us to work with. It currently lives on our data portal here.
The dataset contains all the registered NPOs in the country (as of 2014). To filter out only ECD centres, we can use Socrata’s filter feature. Filter the Category 2 column to include only Child Services. You can find the result here. Now we have a list of all the registered organisations in the country that provide services to children. How do we extract only those in Zululand?
It would be nice if our database contained a structured address format so that we could filter by municipality. Unfortunately it doesn’t. It contains a low quality address field. Many of the addresses are incomplete or outright junk. This one for instance seems fine:
Koningsdal Farm 220
Babanango
3850
This one less so:
Next To Nongoma Lodge
Lot 115
Masson Street
What to do?
There is no clean way to do it, but perhaps a little bit of hacking can get us a reasonable dataset.
Here’s how I went about it.
- Get a list of all the towns, suburbs and villages in Zululand
- Run through each of the addresses in our ECD database and look to see if the address contains the name of a place in Zululand.
Easy. Here are the steps that I took:
Compile a list of places in Zululand
The 2011 Census shapefiles are very useful. In particular, StatsSA defines two handy geographies, mainplaces and subplaces. A mainplace roughly maps to a town or large suburb. A subplace could be a village or a suburb. If we filter only those places within Zululand then we’re golden. My tool of choice is QGIS. Here’s how I did it:
Firstly I loaded up my mainplaces shape file. By default, all mainplaces are selected:
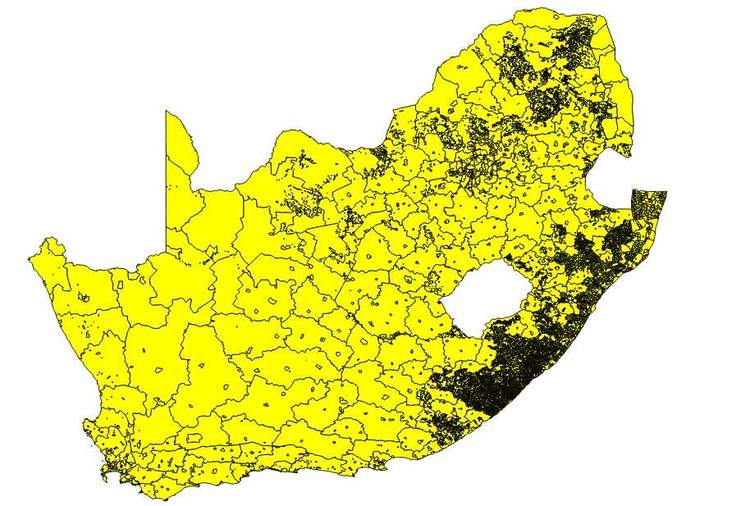
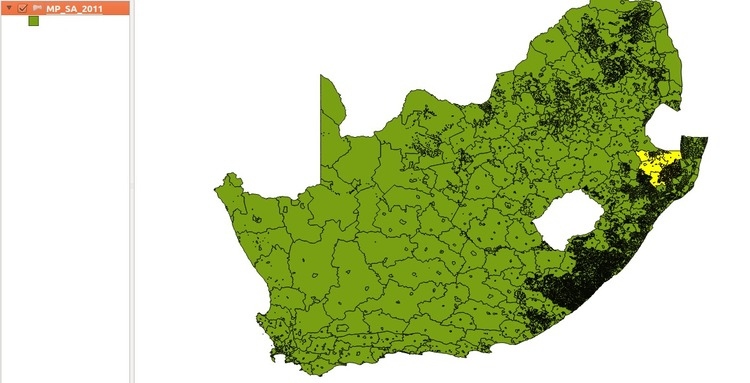
Then open up the attribute table and filter only this mainplaces that can be found in district DC26 (Zululand).

Now only the Zululand shapes are selected:
If we now save this layer as a csv we will get a file containing mainplaces as one of the columns.
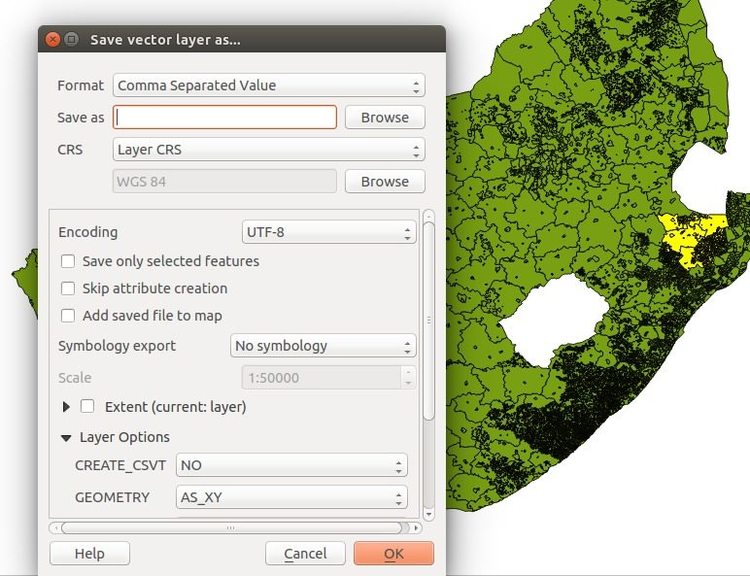
Copy that column and put it into a zululand_places.txt file. Do that same thing with the subplaces shapefile. After you clean this text file a little (remove SP and NU suffixes, and some other junk), you will get a file that looks something like this.
Using this file, we can create a regular expression which searches for Zululand placenames in a string.
import re
field_names = 'id,source_url,status,category,fax,name,postal_address,phone,reg_no,physical_address,legal_form,reg_date,contact_name,email,reg_status_cell,reg_no_cell,category1,category3,category2'.split(',')
def gen_re():
places = [el.strip() for el in open('zululand_places.txt')]
piped = "|".join(places)
return re.compile(piped)
We then run through the npo database and filter out only those NPOs whose addresses contain a Zululand placename in them:
import csv
re_place = gen_re()
reader = csv.DictReader(open('npo.csv'))
with open('ecd_npo.csv', 'w') as fp:
writer = csv.DictWriter(fp, field_names)
for datum in reader:
address = datum['physical_address']
if re_place.search(address):
writer.writerow(datum)
Viola! A list of Zululand ECD centres. Sure, this was a little quick and dirty. We’ve missed some centres along the way and probably added a few that shouldn’t be there. Some manual auditing might help clean this list a little further. In all, we now have approximately 1000 centres in our database.
And that’s it. Using a few really simple steps, we are able to intelligently filter a very large dataset of relatively dirty data into a much smaller, targeted dataset.


